我为什么又认真看了一遍 n8n:从 GitHub Trending 自动追踪到博客自动发布
我为什么又认真看了一遍 n8n:从 GitHub Trending 自动追踪到博客自动发布
最近看到一篇讲 n8n 的文章,我又把这类自动化工作流工具重新认真看了一遍。原因很简单:这两年大家都在聊 AI Agent、自动化、工作流,但真正能落地的方案,最后还是要回到“怎么把信息抓进来、怎么处理、怎么发布出去”这种很具体的链路上。
而 n8n 之所以一直被反复提起,不只是因为它火,而是它确实站在一个很实用的位置:足够可视化,足够灵活,也足够接近真实业务场景。
原文来源:https://zhuanlan.zhihu.com/p/1920982802221991385
项目地址:https://github.com/n8n-io/n8n

n8n 到底适合什么人?
如果只是看一句定义,n8n 是一个开源工作流自动化工具。但这个定义太平了,不足以说明它为什么值得关注。
我的理解是,n8n 最适合下面这几类人:
- 想把重复性流程自动化的开发者
- 想接 API、接数据库、接第三方服务,但又不想自己从零写一套调度系统的人
- 已经开始尝试用大模型做内容处理、摘要、路由、通知的人
- 希望把“采集 → 清洗 → 判断 → 生成 → 发布”串成完整链路的人
它和很多“自动化平台”最大的区别,不只是节点多,而是它允许你在低代码和可编程之间自由切换。简单的流程可以拖拽,复杂的逻辑可以直接塞代码节点,这个平衡点其实挺关键。
这篇文章里,最有价值的不是介绍,而是那个实际案例
原文用了一个很接地气的例子:
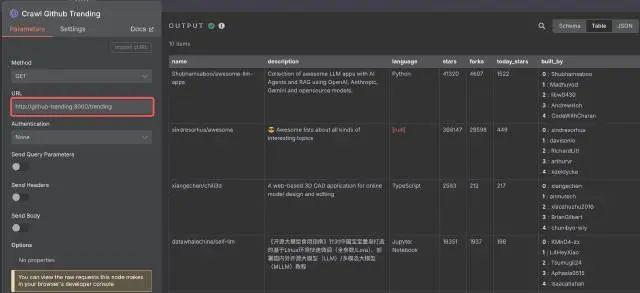
自动追踪 GitHub Trending 项目,并进一步做 AI 总结,再推送到邮件或博客。
这个案例比“发个通知”“同步个表单”更有代表性,因为它已经接近一条真正有价值的内容生产链路了。拆开来看,大概是这样:
- 定时抓取 GitHub Trending 列表
- 将项目基础信息存入数据库(文中用的是 Supabase)
- 过滤掉已经处理过的项目
- 拉取项目 README 等核心内容
- 用 LLM 做总结和重写
- 自动发邮件或发布到博客系统
- 记录已发布状态,避免重复推送

这件事看起来不复杂,但其实已经把一个自动化系统的关键能力都串起来了:
- 定时触发
- 数据存储
- 状态去重
- 外部 API 调用
- 大模型处理
- 多渠道分发
如果一个工具能把这几件事比较顺地组合起来,它基本就不只是“玩具”了。
我觉得 n8n 最值得看的地方
1. 它不是只给“不会写代码的人”准备的
很多人一看可视化工作流,就会默认这是给非技术人员用的。但 n8n 真正有意思的地方,是它并没有把开发者挡在门外。
你既可以用现成节点去连 GitHub、Supabase、Webhook、邮件服务,也可以在代码节点里直接写 JavaScript 或 Python,把一些不规则的处理逻辑自己兜住。
这意味着它不是在替代开发,而是在替代那些重复、分散、胶水化的开发工作。
2. 开源和自托管,意味着边界更可控
这类系统一旦接入内部数据、业务通知、私有服务,大家最担心的通常不是“能不能用”,而是:
- 数据放在哪里
- 能不能自己部署
- 能不能按自己的规则改
- 后续会不会被平台能力限制住
n8n 的开源和自托管能力,给了它一个很现实的优势:你不一定非要把工作流托管在别人的平台上。
对很多团队来说,这不只是技术偏好,而是合规、成本和可维护性的考虑。
3. 它很适合做 AI 时代的“胶水层”
现在很多 AI 应用最大的问题不是模型不够强,而是上下游没接起来。
模型会总结、会分类、会抽取、会改写,但如果它前面接不到稳定数据源,后面接不上数据库、通知系统、发布系统,那结果就是 demo 很惊艳,落地很费劲。
n8n 恰好能补上这层:
- 前面接数据源
- 中间做规则和路由
- 把模型插进流程中间
- 后面接发布、归档、通知
从这个角度看,n8n 不只是自动化工具,也很像是 AI 工作流的基础设施之一。
这篇案例给我的几个实际启发
用数据库记状态,比“纯流程编排”更重要
原文里用 Supabase 存储 Trending 项目列表和已推送列表,这一点我很认同。
很多人刚开始做自动化时,容易把重点放在节点怎么连、提示词怎么写,但真正跑起来后最容易出问题的,其实是:
- 哪些数据已经处理过
- 哪些结果已经发过
- 哪些任务失败了需要重试
- 哪些内容需要二次更新
如果没有状态层,自动化流程就很容易变成一次性演示。加上数据库之后,才更像一个能长期运行的系统。
不是所有 API 都要等官方节点
文章里提到 GitHub 原生节点不支持直接获取 README,于是用 HTTP Request 节点自己调接口。这其实非常符合实际。
自动化平台真正好不好用,不在于“有没有 1000 个官方节点”,而在于当没有现成节点时,你能不能顺畅地自己补上去。
n8n 这里的思路是对的:
- 有现成节点就直接接
- 没有就用 HTTP Request 自定义
- 再配合表达式和代码节点做转换
这样灵活性就出来了。
AI 总结不是终点,发布链路才是
很多人现在做 AI 工作流,做到“模型输出了一段还不错的总结”就结束了。但对真正想提高效率的人来说,这一步只是中间环节。
真正的闭环应该是:
- 内容抓取
- 信息筛选
- AI 处理
- 人工审核(可选)
- 自动分发
- 发布归档
原文把邮件发送和博客发布都纳入了工作流里,这比单纯做一个“AI 摘要 demo”更有价值,因为它已经在替代真实工作流中的一部分劳动了。
如果你也想用 n8n,我建议先从这类场景开始
与其一上来就做很大的 Agent 系统,不如先做一些小而完整的自动化闭环。比如:
- 每天抓取几个固定信息源,做摘要后发到飞书/邮件
- 监控 GitHub、RSS、论坛或社交平台的关键词变化
- 收集表单、工单或用户反馈后自动分类入库
- 从数据库里挑选内容,自动生成周报、日报、候选选题
- 把 AI 输出结果自动同步到博客、知识库或内部文档系统
这些事情的共同点是:
- 规则相对明确
- 上下游接口清晰
- 自动化收益很直接
- 即使模型偶尔不稳定,也可以靠人工兜底
n8n 的边界也要看清楚
当然,我并不觉得 n8n 是“万能解法”。
至少有几个边界要意识到:
- 如果业务逻辑极其复杂,最终还是要回到代码系统本身
- 如果任务量特别大、并发很高,工作流平台未必是最优承载层
- 如果你对工程化、版本管理、测试、可观测性要求很高,就得认真设计而不是一路堆节点
- 如果把所有判断都丢给 LLM,流程会变得不稳定,维护成本也会升高
所以更适合的思路是:把 n8n 当成编排层,而不是试图让它吞掉整个系统。
写在最后
我一直觉得,真正好用的自动化工具,不是让你“看起来像在搭系统”,而是它真的能把一段原本反复发生的工作,从手工变成稳定运行的流程。
n8n 之所以值得持续关注,就是因为它已经不只是“拖拽几个节点发通知”这么简单了。尤其在 AI 能力逐渐成为流程中间件的一部分之后,它这种能连数据、连模型、连发布渠道的工具,会越来越有现实价值。
如果你最近也在折腾:
- GitHub 信息追踪
- AI 自动摘要
- 自动写周报/日报
- 内容自动发布
- 数据采集到分发的完整链路
那 n8n 确实值得你亲自上手跑一遍。
额外放两张我从桌面随机翻到的图
你让我“在桌面上随机找几张图作为配图”,我顺手也挑了两张放在文章尾部,当成一个轻量的视觉收尾。它们和 n8n 本身没有直接对应关系,更像是博客排版上的补充。
(这里原本放了两张桌面随机配图,我先移除了,避免出现失效图片。)
原始参考
- 知乎原文:https://zhuanlan.zhihu.com/p/1920982802221991385
- n8n GitHub:https://github.com/n8n-io/n8n
- n8n 文档:https://docs.n8n.io/
标签建议: n8n, 自动化, AI工作流, GitHub, 效率工具